In this post we will se the advantages that Helm gives to the team in terms of managing Kubernetes releases.
What is Helm? : As apt-get, yum, yarn, npm , brew and others package manager, Helm do the same but oriented to Kubernetes.
So how help me? Basically allow you to package your different yaml files in to a chart and helm create a history inside Kubernetes for that reason do an upgrade or a rollback is less complicate.
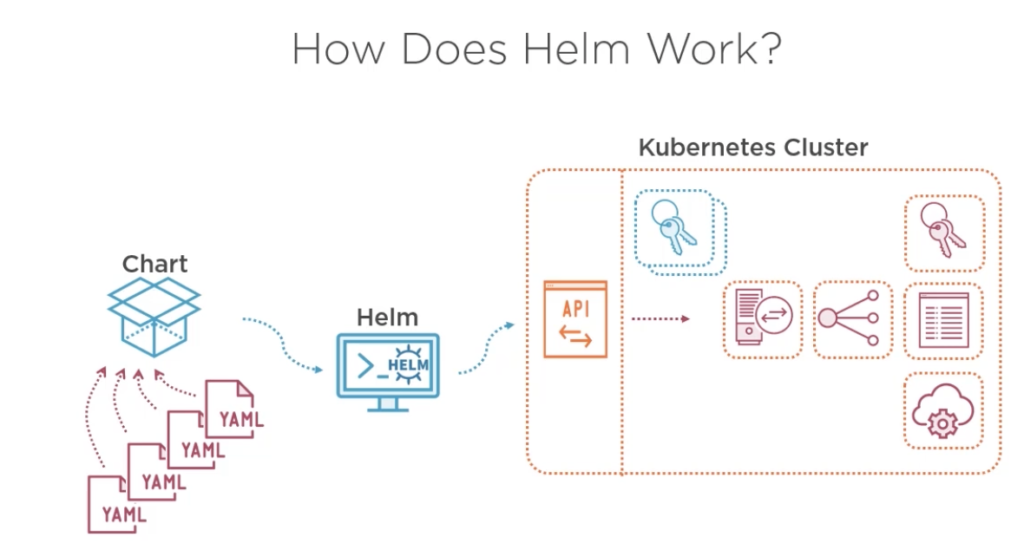
As the image above, helm packages all your yaml files and easily deploy your workloads besides helm maintain a list of all changes and releases and can merge changes out of helm charts yo keep the desired state, furthermore Helm allows you to create aa complex interpolation to create templates and be your workload more reusable. for example imagine that you have a complex deployment (Ingress, services, deployment replicas pods, with front end applications, backend and database workloads) then you could simply release a version of this just changing the name of your deployment like:
# this demo is using helm version v3.6.2+gee407bd
helm install dev myfisrtchart
helm install qa myfisrtchart
helm install prod myfisrtchart
In this demo we will make a simple helm chart.
to create a new helm char we are going to do:
- a simple hello world using nginx:alphine
- get the yaml files and create a service
- create the helm structure
- create a parameter to play with replicas
- install the helm
- upgrade helm
- and delete the helm deploy
# create a repo mkdir -p mychart/templates cd mychart # create the next file Chart.yaml and copy an paste these lines. nano Chart.yaml #--- paste apiVersion: v2 name: mytestdeploy appVersion: "1.0" description: A Helm chart for xtian testing 1.0 version: 0.1.0 type: application #
Create the deployment yaml file
kubectl create deployment helm-httpd-frontend --replicas=3 --image=httpd:2.4-alpine --dry-run=client -o yaml > sample-templates/deployment.yaml
Folder structure most be like this:

Now is just mater to install our service with helm:
helm install myfirst-deploy mychart/ NAME: myfirst-deploy LAST DEPLOYED: Tue Jul 6 12:24:11 2021 NAMESPACE: default STATUS: deployed REVISION: 1 TEST SUITE: None #test it kubectl get deploy -n default
Now we are going to add some vales to be replaces by a values file, this is not the only method to make your chart more dynamic, there ame other methods like env variables, .json schema even we can use some functions and pipes. To know more go to: https://helm.sh/docs/chart_template_guide/variables/
add a values.yaml with this
replicas:
replicas_test: 2
# modify the sample-deployment in line 9
replicas: {{ .Values.replicas.replicas_test }}

$ helm upgrade myfirst-deploy mychart Release "myfirst-deploy" has been upgraded. Happy Helming! NAME: myfirst-deploy LAST DEPLOYED: Tue Jul 6 12:35:58 2021 NAMESPACE: default STATUS: deployed REVISION: 2 TEST SUITE: None
now we have an easy way to manage replicas with values in helm

This was a simple poc with helm of course there are a lot of capabilities that can be added to your chats so hop this can be useful to you. The code for this labs is in: https://github.com/xRegner/helm-pininos
Best. xtian – Regner























{kind=link}
{kind=link}